因为是feedburner的feeds,所以我就转过来。
Concurrency is a Myth in Ruby
Concurrency introduces parallelism into our applications, and threading is, of course, one way to achieve concurrency. But it turns out that in Ruby, this relation is not transitive: execution parallelism is not the same thing as threading. In fact, if you’re looking for parallelism in your Ruby application, you should be looking at process parallelism instead. So why is that?
Ruby under the covers: Global Interpreter Lock
To understand what’s going on, we need to take a closer look at the Ruby runtime. Whenever you launch a Ruby application, an instance of a Ruby interpreter is launched to parse your code, build an AST tree, and then execute the application you’ve requested – thankfully, all of this is transparent to the user. However, as part of this runtime, the interpreter also instantiates an instance of a Global Interpreter Lock (or more affectionately known as GIL), which is the culprit of our lack of concurrency:
Global Interpreter Lock is a mutual exclusion lock held by a programming language interpreter thread to avoid sharing code that is not thread-safe with other threads. There is always one GIL for one interpreter process.Usage of a Global Interpreter Lock in a language effectively limits concurrency of a single interpreter process with multiple threads — there is no or very little increase in speed when running the process on a multiprocessor machine.
Deciphering the Global Interpreter Lock
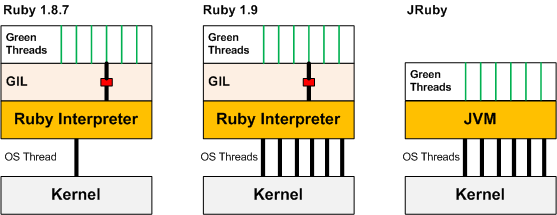
To make this a little less abstract, let’s first look at Ruby 1.8. First, a single OS thread is allocated for the Ruby interpreter, a GIL lock is instantiated, and Ruby threads (‘Green Threads‘), are spooled up by our program. As you may have guessed, there is no way for this Ruby process to take advantage of multiple cores: there is only one kernel thread available, hence only one Ruby thread can execute at a time.
Ruby 1.9 looks much more promising! Now we have many native threads attached to our Ruby interpreter, but now the GIL is the bottleneck. The interpreter guards itself against non thread-safe code (your code, and native extensions) by only allowing a single thread to execute at a time. End effect: Ruby MRI process, or any other language which has a Global Interpreter Lock (Python, for example, has a very similar threading model to Ruby 1.9) will never take advantage of multiple cores! If you have a dual core CPU, you’ll have to run two separate processes.
JRuby is, in fact, the only Ruby implementation that will allow you to natively scale your Ruby code across multiple cores. By compiling Ruby to bytecode and executing it on the JVM, Ruby threads are mapped to OS threads without a GIL in between – that’s at least one reason to look into JRuby.
Process parallelism
The implications of the GIL are surprising at first, but it turns out the solution to this problem is not all that complex: instead of thinking in threads, think how you could split the workload between different processes. Not only will you bypass an entire class of problems associated with concurrent programming (it’s hard!), but you are also much more likely to end up with a horizontally scalable architecture for your application. Here are the steps:
- Partition the work, or decompose your application
- Add a communications / work queue (Starling, Beanstalkd, RabbitMQ)
- Fork, or run multiple instances of you application
- Not surprisingly, many of the Ruby applications have already adopted this strategy: a typical Rails deployments is powered by a cluster of app servers (Mongrel, Ebb, Thin), and alternative strategies like EventMachine, and Revactor (equivalents of Twisted in Python) are gaining ground as a simple way to defer and parallelize your network IO without introducing threads into your application.
虽然本文是介绍Ruby1.8、1.9和JRuby对线程的不同实现。但是却清晰的解释了线程安全的意义,还有为什么MRI(或者同样使用GIL的CPython)需要使用多进程模型部署。再延伸我们可以知道Apach上面的Mod_rails(Passenger和Ruby Enterprise Edition)还有Mod_python的神奇之处,他们都hack并实现了使用fork让进程共享内存。最后本文还同样引出了为什么传统Ruby和Python应用只有使用多进程才可以利用多个CPU,还有为什么Twisted和EventMachine使用了单进程单线程+event IO的模型。