现在1.5T硬盘的价格是899(以前几日购入的价格),现在的市场价可能已经可以接近800。它格式化后容量是1.36TB(以我格式化为Mac使用的HFS+计算)。1.36TB应该等于1392GB。1GB的价格是899/1392 = 0.6458(元/GB)。目前DVD盘片,三菱的50P桶装盘片价格是95,而威宝(三菱子品牌)的价格是75,太阳锈电的盘片已经买不到了(按理说价格更高一些),这样我们可以按照居中的80元一桶基本靠谱的DVD+R盘片(50P)。我这里使用每张盘片4.25GB计算(可以刻录4.3xG,不过个人习惯是小于4.3G,而且由于文件大小不一,经常会有浪费,所以这种计算这理想个值),那么1GB的价格是80 / 4.25 / 50 = 0.3765 (元/GB)。这样计算的话两种存储方式的价格在一个数量级。
作为数据存储,以前我的习惯是重要的盘片刻两张,而且使用两种不同的盘片品牌(因为它们不同批次的衰老曲线完全不同,我遇到过很多批次的DVD盘片会在几个月后出现大量数据坏块),这样存储价格就要翻番。而硬盘存储也会遇到同样的问题,我们一般会使用Raid解决。如果使用简单的Raid 1或者JBOD则也同样是存储成本翻番,如果使用Raid5的话(3+1,利用率62%,则成本会好一些),但是加上支持Raid的设备的话Raid 5可能比翻番还要贵一些(Raid 5控制器比较贵,因为基本上只能见到硬Raid 5)。这段考虑的问题基本上不会对两者的对比产生太大影响,但是证明两者如果要相对于自己来说保证它们的可靠性要花费的成本都基本上要翻番。
但是我们这里要对比另外一个成本。使用成本。由于DVD刻录无法无人值守,所以时间成本非常高。在工作以后,我们的剩余时间很少,时间就更加宝贵。我观察到一个现象,就是我刻录的光盘大都出现在我的高中后2年(99-2000)还有大学4年与研究生的前一年半(2000-2006)中。后来刻盘的数量就直线下降了,大部分数据都留在了硬盘里面。主要就是没有那么多时间整理数据并刻盘,一般来说刻录只占准备时间的1/4,另外1/4可能在寻找刻盘的资源(如电影、软件等),2/4的时间在整理和享受这些资源,最后的1/4是刻盘的时间。但是由于把数据切分为适合刻录的容量是很费时间和精力的,而这部分又没有直接的经济价值,所以这个浪费是一定要想办法消除的。消除的最有效办法是不制造这么多数据,不去备份它们,这个我们另说。主要说是否可以不刻录,而让他们在硬盘上等待被删除或者享受后删除。大部分时间,我遇到的问题是硬盘不够用,所以我的cache就不够用,这些资源经常要被我暂时移动到光盘上,这是我刻盘的主要理由。但是不幸的是,这些盘一般也是最早被我抛弃的。
下面进入正题,由于前面分析的存储成本上硬盘已经不到光盘存储成本的2倍(我的计算结果是1.7倍),而硬盘会极大的缩短备份时间,所以已经完全没有必要选择使用光盘备份了(光盘目前只适合分发)。下面是一些原因:
- 光盘的可靠性太差,而硬盘在使用Raid后可靠性会比光盘强很多(这个待我差好资料再讨论)。
- 硬盘存储在5年左右后完全可以通过非常廉价的转存来实现升级,而光盘不可以(如果把几百张DVD转存到蓝光是多么的可怕?)。
- 硬盘的传输速率比光盘高很多,现在的硬盘在使用SATA的时候可以达到90MB/s以上,而DVD+R在16x下的速度是6分钟刻录4.7GB(也就是0.78G每分钟,合成13.312MB/s)。在使用USB接口的时候硬盘一般也可以达到40MB/s以上的速度,比DVD要快很多很多。而且由于不用切分,硬盘备份是非常简单的。
- 硬盘是随机读写设备,而光盘是顺序只读设备。所以硬盘可以方便的管理,删除、移动、重命名,好比写程序的时候可以实现不断的重构。而光盘则只能整张扔掉或者重写(可读写的光盘由于速度和可靠性的原因这里就不讨论了),这是最为讨厌的Bad smell。
- 体积!1.5TB硬盘在Raid 1以后的体积一般是18cm x 18cm x 18cm。但是这些数据需要326张DVD……326张DVD的体积大概是15cm x 15cm x 58.56cm,这个是不装在盘包里面的价格,装到盘包里面体积会翻翻。那么大概是5倍的体积……
- 在搜索的时候,硬盘可以使用操作系统提供的搜索功能。而光盘你需要使用where is it这样的软件来管理,其麻烦程度比使用操作系统的索引查找要高上很多,主要是这会浪费掉你很多宝贵的时间。
经过分析,我决定以后放弃使用光盘存储。光盘存储只会作为暂时的数据分享和重要数据的异地备份。这样我一年就可以节省下相当可观的时间了。而且也可以给我的笔记本剩下几个光驱的钱,何乐而不为?
 一块儿到来的还有一个Tp-Link的WL-841N的802.11n路由器,300Mbps的无限连接,评测的数据是可以达到100Mbps也就是我家有线网的速率。
一块儿到来的还有一个Tp-Link的WL-841N的802.11n路由器,300Mbps的无限连接,评测的数据是可以达到100Mbps也就是我家有线网的速率。 型号是ST31500341AS,就是1500GB空间,375G单碟,4碟装,台式机硬盘。听说CC1G这个固件版本不是很好,我做外置硬盘倒是无所谓。
型号是ST31500341AS,就是1500GB空间,375G单碟,4碟装,台式机硬盘。听说CC1G这个固件版本不是很好,我做外置硬盘倒是无所谓。 现在的Seagate使用了和WD一样的反装电路板,两年以来这个技术已经普及了。
现在的Seagate使用了和WD一样的反装电路板,两年以来这个技术已经普及了。 装到盒子里面去。我使用的是WD的硬盘盒,实际上是拆机货。WD的外置盒子其实质量很好,没有访问的时候会自动断电休眠,还有个好处就是便宜。
装到盒子里面去。我使用的是WD的硬盘盒,实际上是拆机货。WD的外置盒子其实质量很好,没有访问的时候会自动断电休眠,还有个好处就是便宜。 控制芯片是目前高端盒子常见的Oxford semiconductors出的OX921S,这个盒子是三个里面最简单的,单USB。
控制芯片是目前高端盒子常见的Oxford semiconductors出的OX921S,这个盒子是三个里面最简单的,单USB。 他们叠放在我的桌子上就是这么个效果,就是那个破音箱上面的三个发光的小家伙。这个照片是上周日的,实际上硬盘还不是1.5T的,不过意思是一样的。
他们叠放在我的桌子上就是这么个效果,就是那个破音箱上面的三个发光的小家伙。这个照片是上周日的,实际上硬盘还不是1.5T的,不过意思是一样的。


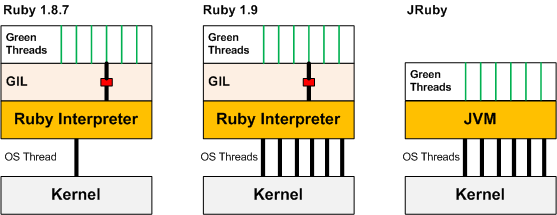
 Concurrency introduces parallelism into our applications, and threading is, of course, one way to achieve concurrency. But it turns out that in Ruby, this relation is not transitive: execution parallelism is not the same thing as threading. In fact, if you’re looking for parallelism in your Ruby application, you should be looking at process parallelism instead. So why is that?
Concurrency introduces parallelism into our applications, and threading is, of course, one way to achieve concurrency. But it turns out that in Ruby, this relation is not transitive: execution parallelism is not the same thing as threading. In fact, if you’re looking for parallelism in your Ruby application, you should be looking at process parallelism instead. So why is that?